NYUv2 Scene

CMP [CVPR '24]
![CMP [CVPR '24]](./static/demos/base_demo_v3.gif)
Ours [CVPR '25]
![Ours [CVPR '25]](./static/demos/ours_demo.gif)
Demonstrating robust continual depth completion: performance over the course of training in the challenging mixed setting of adapting from indoor to outdoor environments.
We present ProtoDepth, a novel prototype-based approach for continual learning of unsupervised depth completion, the multimodal 3D reconstruction task of predicting dense depth maps from RGB images and sparse point clouds. The unsupervised learning paradigm is well-suited for continual learning, as ground truth is not needed. However, when training on new non-stationary distributions, depth completion models will catastrophically forget previously learned information. We address forgetting by learning prototype sets that adapt the latent features of a frozen pretrained model to new domains. Since the original weights are not modified, ProtoDepth does not forget when test-time domain identity is known. To extend ProtoDepth to the challenging setting where the test-time domain identity is withheld, we propose to learn domain descriptors that enable the model to select the appropriate prototype set for inference. We evaluate ProtoDepth on benchmark dataset sequences, where we reduce forgetting compared to baselines by 52.2% for indoor and 53.2% for outdoor to achieve the state of the art.
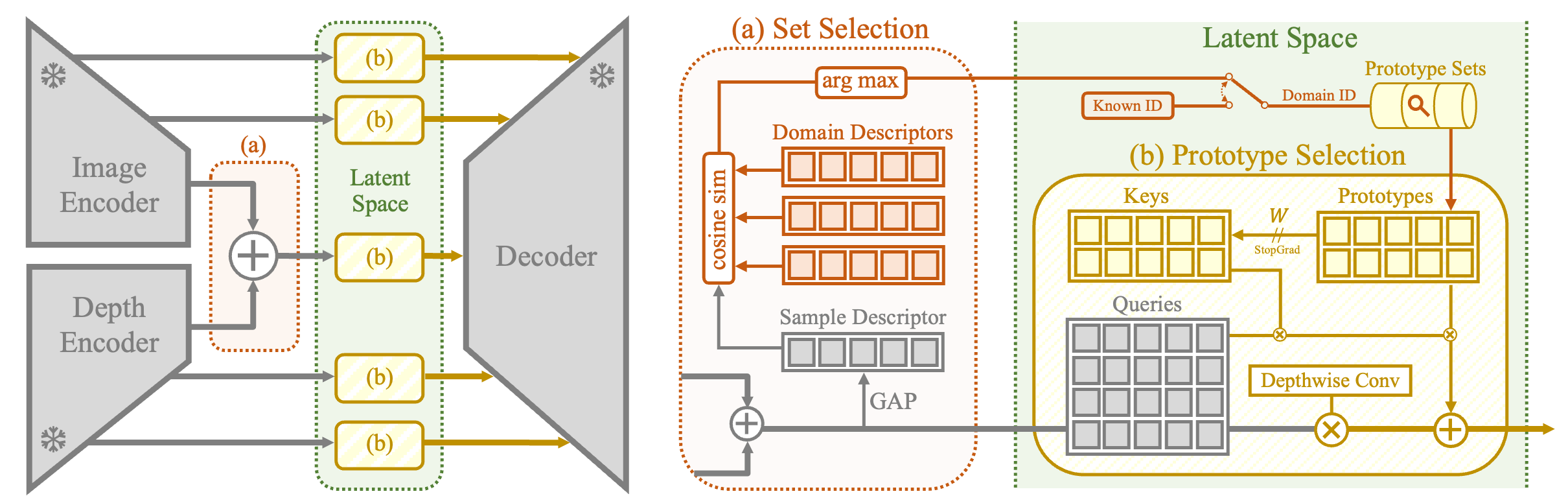
Overview of ProtoDepth. (a) In the agnostic setting, a prototype set is selected by maximizing the cosine similarity between an input sample descriptor and the learned domain descriptors. In the incremental setting, the domain identity is known. (b) At inference, the similarity between the frozen queries and the keys of the selected prototype set determines how the learned prototypes contribute as local (additive) biases to the latent features. Additionally, a global (multiplicative) bias is applied using a 1×1 depthwise convolution.
Qualitative comparison of ProtoDepth and baseline methods using VOICED on KITTI after continual training on Waymo. (a) Input sample from KITTI, (b) Baseline methods exhibit significant forgetting, particularly for small-surface-area objects (e.g., street signs and lamp posts) where sparse depth is limited, and photometric priors from KITTI are critical. In contrast, ProtoDepth produces high-fidelity depth predictions, effectively mitigating forgetting despite the large domain gap between KITTI and Waymo.
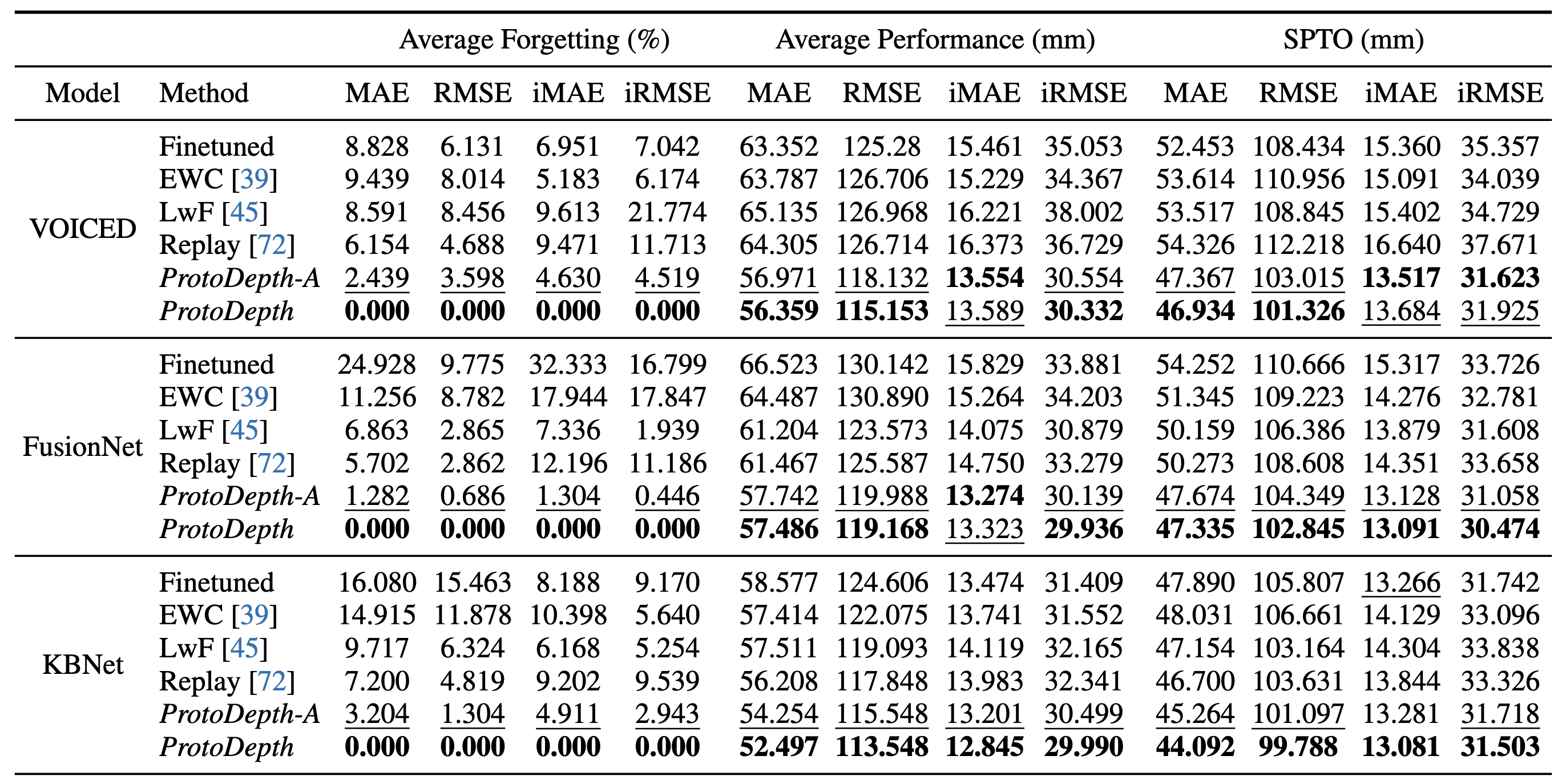
Quantitative results on indoor datasets. Models are initially trained on NYUv2 and continually trained on ScanNet, then VOID.
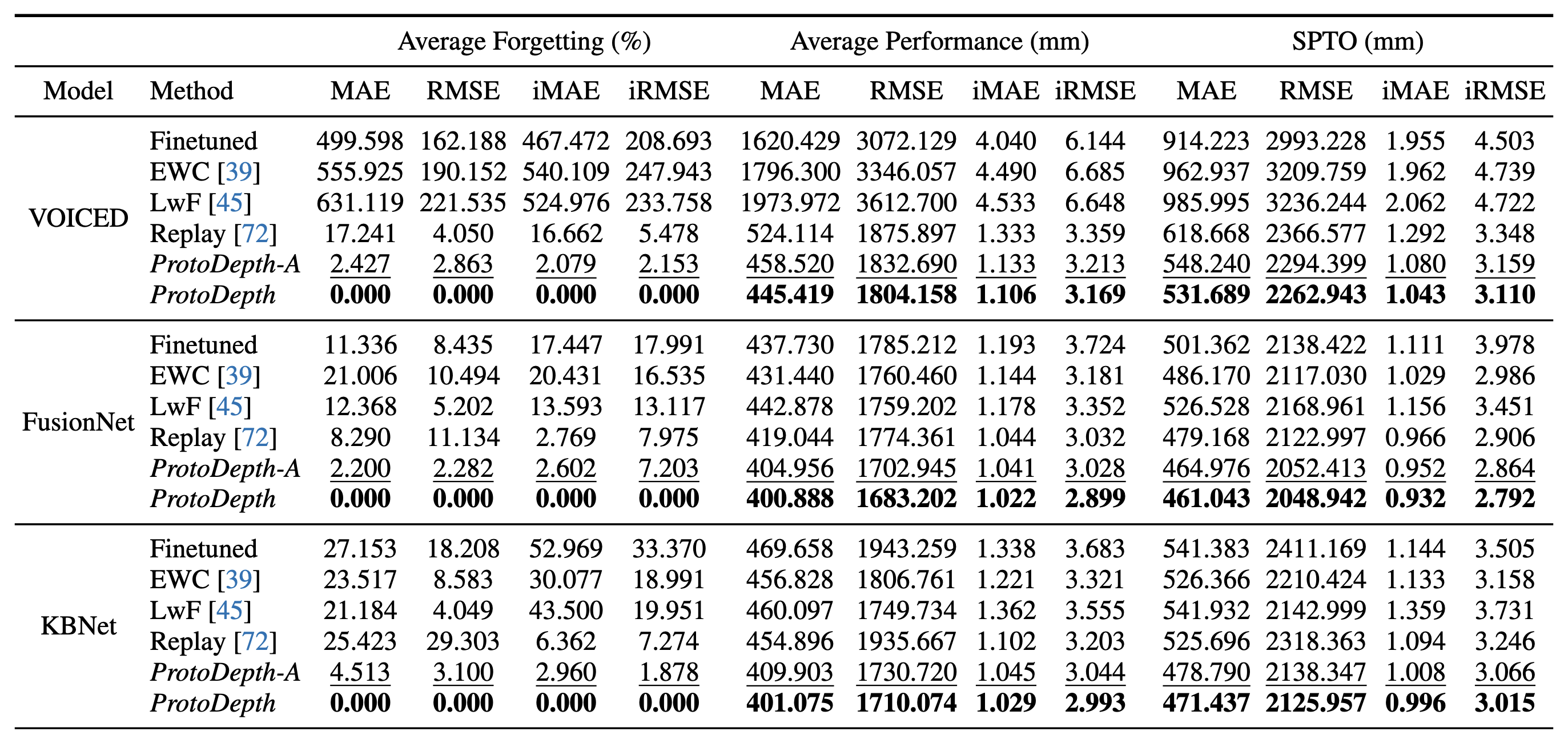
Quantitative results on outdoor datasets. Models are initially trained on KITTI and continually trained on Waymo, then VKITTI.
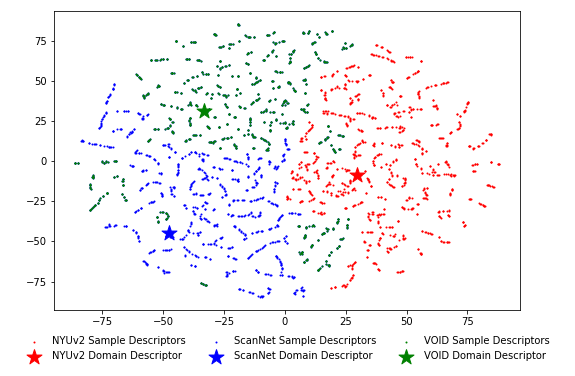
t-SNE plot of KBNet sample descriptors for indoor validation datasets (NYUv2, ScanNet, VOID) and their respective domain descriptors learned during training in the agnostic setting. While most sample descriptors align closely with their respective domain descriptors, some overlap enables cross-domain generalization, improving performance in challenging scenarios.
@article{rim2025protodepth,
title={ProtoDepth: Unsupervised Continual Depth Completion with Prototypes},
author={Rim, Patrick and Park, Hyoungseob and Gangopadhyay, S and Zeng, Ziyao and Chung, Younjoon and Wong, Alex},
journal={arXiv preprint arXiv:2503.12745},
year={2025}
}